

Pareto Distribution#
Univariate, Continuous, Asymmetric, Non-Negative, Heavy-tailed
The Pareto distribution is a continuous probability distribution, known for following a power-law and having a heavy right tail. It is defined by two parameters: the scale parameter \(m\) and the shape parameter \(\alpha\).
It was originally used to describe the distribution of wealth in society where a small proportion of the population holds a large proportion of the wealth (the “80-20 rule”). It has since been used in various fields to describe a wide range of phenomena where events get rarer at greater magnitudes.
Key properties and parameters#
Support |
\(x \in [m, \infty)\) |
Mean |
\(\frac{\alpha m}{\alpha - 1}\) for \(\alpha > 1\) |
Variance |
\(\frac{m^2 \alpha}{(\alpha - 1)^2 (\alpha - 2)}\) for \(\alpha > 2\) |
Parameters:
\(m\) : (float) Scale parameter, \(m > 0\).
\(\alpha\) : (float) Shape parameter, \(\alpha > 1\).
Probability Density Function (PDF)#
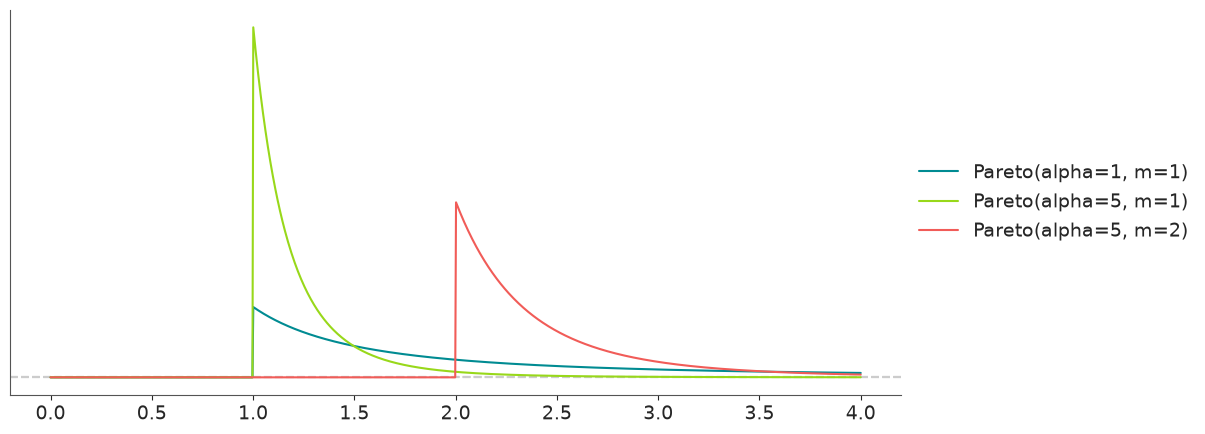
Cumulative Distribution Function (CDF)#
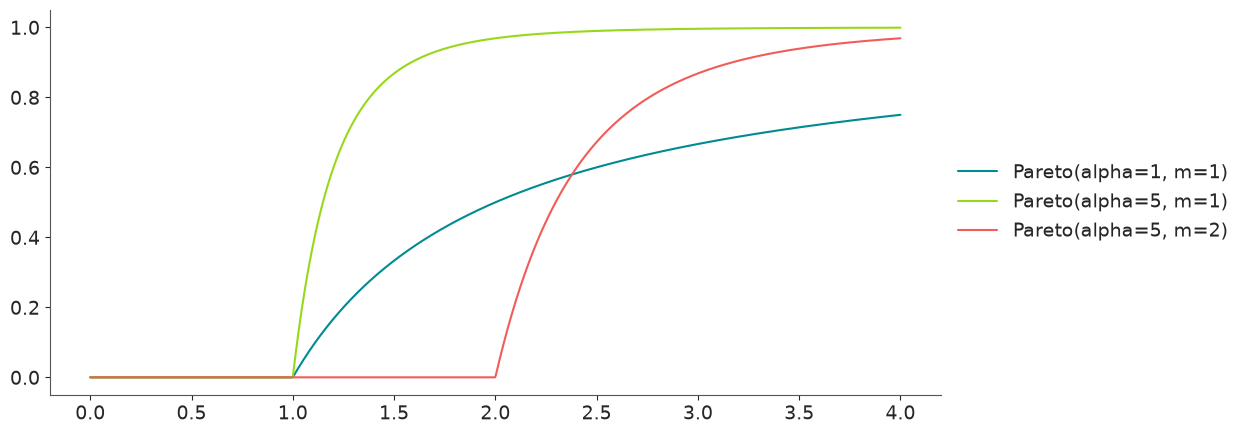
See also
Related Distributions:
Exponential Distribution - If X is Pareto distributed, with scale parameter \(m\), and shape parameter \(\alpha\), then \(Y = log(X/m)\) is exponentially distributed with rate parameter \(\lambda = \alpha\).
Log-Normal Distribution - Also used for modeling positive, skewed data with long tails. The log-normal distribution allows for more flexibility in shaping the tail behavior compared to the Pareto distribution.